- 1 Exploring the dialect survey data
- 2 Making choropleth maps
- 3 Performing local spatial autocorrelation
GIS mapping in R - Part 3
[Mapping dialect survey data]
George Bailey
20/07/2023
Home Part 1 Part 2 Part 3 Part 4
Techniques we’ll cover in this part:
- performing point-in-polygon aggregation
- finding the geographic centroid of shapes/areas
- performing local spatial autocorrelation for smoothing
- performing Voronoi tessellation (based on major towns/city centroids) [coming soon]
In this section we’ll be working with our first proper linguistic dataset, mainly to put many of the techniques covered so far into practice - but there are a few new things to cover as well.
We’re working with a sample of the responses to the long-running Our Dialects survey, which collects usage data on a range of dialectal features across the UK by asking questions such as:
- what word do you use to refer to the evening meal?
- do the words fur and bear rhyme for you?
- do the words thin and fin sound the same or different for you?
- could you use the phrase we was waiting for you?
As usual, load in the sf, tidyverse, rmapshaper and mapview packages if they aren’t already (also pryr if you want to check the object size of your shapefiles before plotting)
library(sf)
library(tidyverse)
library(rmapshaper)
library(pryr)
library(mapview)1 Exploring the dialect survey data
Read in the dialect survey dataset and start exploring it:
dialect <- read_csv("data/dialect_survey.csv")It has 6000 rows (randomly sampled from the full 14,000-row dataset) and 41 columns:
dim(dialect)## [1] 6000 38Exercise
Explore the dataset to see:
- what columns of metadata are included
- what dialect features are included
- how responses to each of the three types of dialect features are coded, i.e. lexical vs phonological vs grammatical variables (hint: use
table()on a particular column to list its unique values and the frequency of each) - how missing values are represented (this will become important later!)
Answers
Checking the columns of demographic metadata:
Show Code
Show Output
These are the 9 lexical variables:
Show Code
Show Output
Checking how they’re coded:
Show Code
Show Output
These are the 13 phonological variables:
Show Code
Show Output
Checking how they’re coded:
Show Code
Show Output
Show Code
Show Output
These are the 7 grammatical variables:
Show Code
Show Output
Checking how they’re coded:
Show Code
Show Output
Just like with the Twitter dataset, before we perform any geospatial analysis we first need to transform this into a shapefile based on the lat/long values
dialect <- dialect %>%
st_as_sf(coords = c("long", "lat"))Because we have the region column, we can already calculate some summary statistics, e.g. the proportion of people from Yorkshire who rhyme the words foot and cut (i.e. who don’t have the FOOT-STRUT split)
dialect %>%
st_drop_geometry() %>%
filter(region == 'Yorkshire and The Humber') %>%
count(foot.cut) %>%
mutate(rate = n / sum(n))## # A tibble: 2 × 3
## foot.cut n rate
## <chr> <int> <dbl>
## 1 don't rhyme 164 0.206
## 2 rhyme 633 0.794So about 20% of people from Yorkshire have the vowel split - compare this to people from the South East, where 96% of people report it!
dialect %>%
st_drop_geometry() %>%
filter(region == 'South East') %>%
count(foot.cut) %>%
mutate(rate = n / sum(n))## # A tibble: 2 × 3
## foot.cut n rate
## <chr> <int> <dbl>
## 1 don't rhyme 600 0.955
## 2 rhyme 28 0.0446This is quite a blunt way of approaching the geographic analysis though - there are only 9 regions of England but we know that dialect patterns are much more local and finer-grained than this!
Let’s perform some point-in-polygon aggregation to add other geocoded columns we can use in the analysis. Let’s start with postcode area (e.g. the ‘YO’ in YO10 5DD). We used postcode areas in Part 2 of this workshop so you should already have the uk.areas shapefile in your R environment, but if not make sure you load it in first:
uk.areas <- read_sf("shapefiles/uk-areas.shp") %>%
ms_simplify(keep = 0.01)We can use the same methods from before to perform point-in-polygon aggregation:
- Set a CRS to the
dialectdataset, and make sure it’s the same as theuk.areasshapefile - Use
st_make_valid()to ensure that the shapefile is topologically valid after we simplified the geometries - Use
st_join()to overlay the two shapefiles and perform the point-in-polygon aggregation
st_crs(dialect) <- st_crs(uk.areas)
uk.areas <- st_make_valid(uk.areas)
dialect <- dialect %>%
st_join(uk.areas, join = st_within)This should have added a new column named pc_area, corresponding to the postcode area for each respondent.
Has the geocoding actually worked? Let’s look at a random sample of the data, focusing on the geometry column (our original lat/long values), the new pc_area column we’ve just geocoded, and the region column we already had in the dataset:
dialect %>%
select(geometry, pc_area, region) %>%
sample_n(10)## Simple feature collection with 10 features and 2 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: -3.126306 ymin: 51.00715 xmax: -0.1171217 ymax: 53.85991
## Geodetic CRS: WGS 84
## # A tibble: 10 × 3
## geometry pc_area region
## * <POINT [°]> <chr> <chr>
## 1 (-2.395596 53.37376) WA North West
## 2 (-2.740788 53.40464) WA North West
## 3 (-2.289099 53.85991) BB North West
## 4 (-0.1171217 51.00715) RH South East
## 5 (-2.075188 52.35304) B West Midlands
## 6 (-0.3212205 53.76869) HU Yorkshire and The Humber
## 7 (-0.7636585 51.30798) GU South East
## 8 (-1.883778 52.43449) B West Midlands
## 9 (-1.121013 53.52484) DN Yorkshire and The Humber
## 10 (-3.126306 53.39714) CH North WestWell it’s done something, but I don’t have the encyclopedic knowledge of all latitude and longitude values to know if those postcode areas have been assigned correctly. Let’s plot only the responses geocoded as coming from ‘YO’ (Yorkshire), ‘M’ (Manchester) or ‘B’ (Birmingham)
ggplot(uk.areas) +
geom_sf() +
geom_sf(data = filter(dialect, pc_area %in% c('YO', 'M', 'B')),
aes(colour = pc_area)) +
theme_void()
Certainly looks right! We do have a few pesky NAs in the pc_area column though, i.e. points that apparently don’t overlap with any polygon in the uk.areas shapefile.
Let’s take a closer look by plotting only these points in an interactive map so we can really zoom in and see where they are
dialect %>%
filter(is.na(pc_area)) %>%
mapview()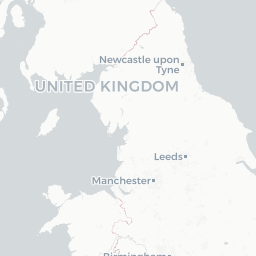
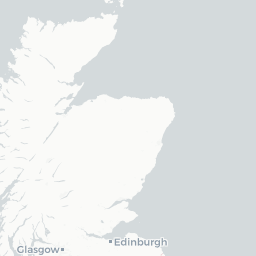

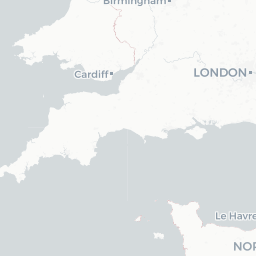

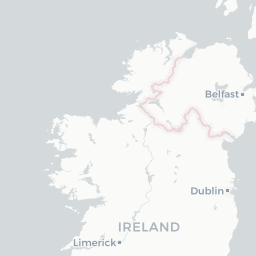
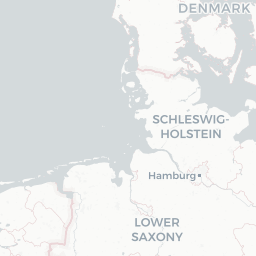
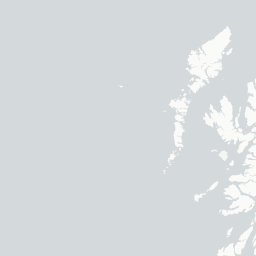
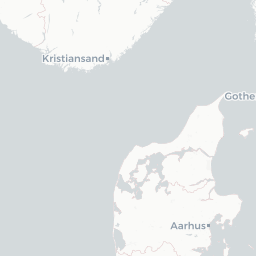
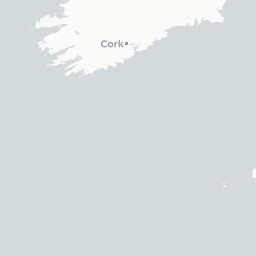
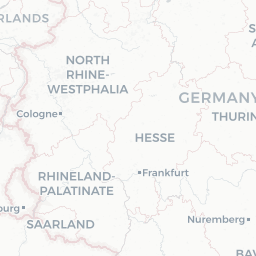
Looks like they’re all points that lie on the coast - this is a case of the geometries not lining up perfectly (possibly because we simplified the uk.areas shapefile) and/or the lat/long values falling very slightly into the sea so they’re technically not overlapping with any of the polygons. Let’s just get rid of them:
dialect <- dialect %>%
filter(!is.na(pc_area))Exercise
Postcode areas are ok, but let’s take it one step further for a more detailed level of geospatial analysis. Following the same methods as above, perform point-in-polygon aggregation for postcode districts (e.g. the ‘YO10’ in YO10 5DD) for each respondent - there are over 2800 of these across Great Britain so we’ll be able to make much more detailed maps.
You can download a copy of the uk.districts shapefile here. A brief note on labels: this shapefile is unfortunately missing the ‘BT’ postcode districts across Northern Ireland so technically it’s a shapefile of Great Britain, not the United Kingdom, but I’m calling it uk.districts for consistency with uk.areas (which does contain the ‘BT’ postcode area)
Answers
Show Code
Show Plot

Show Code
Show Output
Show Code
Show Plot

2 Making choropleth maps
Great - in addition to our actual geometry column (of lat/long points), we now have columns for:
- region (e.g. North West, South East, West Midlands etc)
- pc_area (e.g. YO, M etc)
- pc_dist (e.g. YO10, M45 etc)
This gives us a lot to work with when it comes to investigating regional patterns of dialect use. It means we can plot choropleth maps, i.e. polygons colour-coded with % use of a given linguistic variant, rather than colour-coded point maps (which can become over-crowded with large datasets, as we’ve already seen).
So how do we calculate these percentages? Choropleth maps can only plot the rate of use of a single variant of a single variable at once, so we need to pick what to plot first. How about people who rhyme the words class and farce, which represents a TRAP-BATH split (apologies to the non-sociolinguists among you who have no idea what a TRAP-BATH split is!)
We start by calculating the total number of responses to that variable in each geometry (which means having to filter out the NAs so they aren’t counted). We’ll save this to a dataframe called totals.
totals <- dialect %>%
st_drop_geometry() %>%
filter(!is.na(class.farce)) %>%
group_by(pc_area) %>%
summarise(total = n())
totals## # A tibble: 118 × 2
## pc_area total
## <chr> <int>
## 1 AB 12
## 2 AL 8
## 3 B 70
## 4 BA 28
## 5 BB 86
## 6 BD 36
## 7 BH 10
## 8 BL 76
## 9 BN 18
## 10 BR 5
## # ℹ 108 more rowsThis is a workshop on mapping in R (not on the tidyverse itself!) so I don’t want to spend too much time covering more general data wrangling techniques, but this is a relatively complex ‘pipe chain’ of functions so let’s break it down line by line to see what we just did:
- drop the
dialectgeometries usingst_drop_geometry()to turn it into a regular dataframe filter()out the missing responses in the column of interest (there are lots of missing responses in the dataset because the survey has gone through many iterations with different sets of questions each time)group_by()thepc_areacolumn to split the analysis up by each postcode area- use
summarise()to create atotalcolumn, which is just the total number of rows in each postcode area (after filtering out the NAs of course)
The next step is to count the number of times our chosen response — rhyme — occurs in each postcode area. The code is almost identical to what we just saw, - the only difference is in the filter() command. We save this to a dataframe called counts:
counts <- dialect %>%
st_drop_geometry() %>%
filter(class.farce == 'rhyme') %>%
group_by(pc_area) %>%
summarise(n = n())
counts## # A tibble: 108 × 2
## pc_area n
## <chr> <int>
## 1 AB 3
## 2 AL 7
## 3 B 21
## 4 BA 19
## 5 BB 5
## 6 BD 2
## 7 BH 10
## 8 BL 2
## 9 BN 15
## 10 BR 5
## # ℹ 98 more rowsNotice that the counts dataframe has only 108 rows, compared with 118 rows for totals. This is because counts only lists the postcode areas where the response of interest, in this case rhyme, is reported at least once. If this response is completely absent from a particular postcode area, it won’t be listed here.
This means that when we join together the totals and counts dataframes using left_join(), those postcode areas missing from counts will have NA as their value. We want to replace these NAs with 0 to represent the fact that 0% of the survey participants from that area responded in this way.
The code below does this, and also calculates a prop column as before, which will give a value between 0 and 1 representing the proportion of respondents in each postcode area who rhyme the words. We’ll save this to a new dataframe called props.
props <- left_join(totals, counts) %>%
replace_na(list(n = 0)) %>%
mutate(prop = n / total)
props## # A tibble: 118 × 4
## pc_area total n prop
## <chr> <int> <int> <dbl>
## 1 AB 12 3 0.25
## 2 AL 8 7 0.875
## 3 B 70 21 0.3
## 4 BA 28 19 0.679
## 5 BB 86 5 0.0581
## 6 BD 36 2 0.0556
## 7 BH 10 10 1
## 8 BL 76 2 0.0263
## 9 BN 18 15 0.833
## 10 BR 5 5 1
## # ℹ 108 more rowsThen we can join this dataframe back to our uk.areas shapefile to plot a choropleth map colour-coded by this new prop column:
uk.areas %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = prop)) +
theme_void()
Cool!
The process is the same for grammatical variables: pick your variable (i.e. the column name) and the response you want to plot when performing the filter for the counts dataframe, e.g. filter(give.it.me == 'a'). You might want to plot people who responded with ‘a’ or ‘b’ (which means they either use the phrase themselves, or have heard it used in their area), in which case you’d just change the filter() command to filter(give.it.me == 'a' | give.it.me == 'b').
The process is also the same for lexical variables, but remember that a filter like filter(bread == 'muffin') will only plot people who report use of muffin and no other variant. Recall that many people reported use of more than one variant. To plot everyone who uses a particular variant, whether exclusively or not, you would simply change the filter to filter(str_detect(bread, 'muffin')), using str_detect() to keep rows that contain the string ‘muffin’ somewhere in the response.
Let’s try this 3-step process again to demonstrate:
totals <- dialect %>%
st_drop_geometry() %>%
filter(!is.na(bread)) %>%
group_by(pc_area) %>%
summarise(total = n())
counts <- dialect %>%
st_drop_geometry() %>%
filter(str_detect(bread, 'muffin')) %>% #notice str_detect() here
group_by(pc_area) %>%
summarise(n = n())
props <- left_join(totals, counts) %>%
replace_na(list(n = 0)) %>%
mutate(prop = n / total)
uk.areas %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = prop)) +
theme_void()
Looks like it’s fairly localised! Remember we can use mapview() to generate an interactive map instead, which allows us to zoom in and see in which exact postcode areas muffin is used. Because we specify label == 'pc_area', hovering the mouse over each polygon reveals the postcode area label, but we can also set this to label == 'prop' if you want the hover-over text to display the actual proportion/value itself.
uk.areas %>%
left_join(props) %>%
mapview(zcol = 'prop', label = 'pc_area')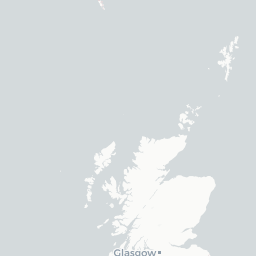



Exercise
Now it’s time to try it yourself: choose different dialect features/variants and make some choropleth maps based on postcode areas and also postcode districts - what are the pros/cons of each type? What interesting patterns of regional variation do you find?
Answers
Show Code
Show Plot

3 Performing local spatial autocorrelation
You might have noticed that with a more fine-grained level of aggregation, i.e. over postcode districts rather than areas, we get (1) more missing values, i.e. postcode districts with no responses, and (2) noisier values, i.e. postcode districts where you get extreme and unreliable percentages because there are only 1 or 2 respondents.
One solution is to perform a kind of smoothing called local spatial autocorrelation. This isn’t just to make prettier maps with less noise: it’s also a robust method for investigating the spatial structure of your data by looking for hot spots or cold spots (you sometimes see this referred to as ‘hot spot analysis’ for that reason). In other words, it looks for polygons/areas that not only have a particularly high (or low) value for your chosen variable, but that are also surrounded by nearby polygons/areas that also have particularly high (or low) values.
This is a technique we used in our recent publication using the Our Dialects survey data, and I’ll walk you through the main steps here.
We need a new package in our arsenal for this: spdep. Let’s install and load it in:
install.packages("spdep")
library(spdep)Step 1: We first need the raw data, so generate your props dataframe just as we did before. Let’s look at who calls a bread roll a cob:
totals <- dialect %>%
st_drop_geometry() %>%
filter(!is.na(bread)) %>%
group_by(pc_dist) %>%
summarise(total = n())
counts <- dialect %>%
st_drop_geometry() %>%
filter(str_detect(bread, 'cob')) %>%
group_by(pc_dist) %>%
count()
props <- left_join(totals, counts) %>%
replace_na(list(n = 0)) %>%
mutate(prop = n / total)
uk.districts %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = prop)) +
theme_void()
Step 2: use st_centroid() to calculate the geographic centroid of each polygon in your shapefile (i.e. each postcode area or district). In this example, we’ll use postcode districts
centroids <- uk.districts %>%
st_centroid() %>%
st_coordinates() %>%
as.data.frame() %>%
rename(centroid_long = X, centroid_lat = Y) %>%
mutate(pc_dist = uk.districts$pc_dist)
head(centroids)## centroid_long centroid_lat pc_dist
## 1 -2.124527 57.13125 AB10
## 2 -2.080886 57.13860 AB11
## 3 -2.162241 57.08594 AB12
## 4 -2.241504 57.11100 AB13
## 5 -2.293247 57.10742 AB14
## 6 -2.211241 57.14225 AB15Here’s what those centroids look like (zoomed in on the North West to make it clearer)
ggplot(uk.districts) +
geom_sf() +
geom_point(data = centroids, aes(x = centroid_long, y = centroid_lat),
size = 0.5, alpha = 0.5) +
coord_sf(ylim = c(53, 54), xlim = c(-3.5, -1.5)) +
theme_void()
Step 3: calculate a spatial weights matrix, which we need to perform the spatial autocorrelation smoothing. This involves taking each polygon centroid, as we just calculated, and working out its k nearest neighbours and its distance from those neighbours. What’s k? Whatever you want it to be! The higher value we set k as, the stronger the smoothing.
We can see below, for the postcode districts around Greater Manchester, how increasing the size of k means we take into account more and more neighbouring polygons.

Let’s set k to 25 for now, and go ahead making our spatial weights matrix:
#add centroids to our props dataframe, and transform into a matrix
props_centroid_matrix <- props %>%
left_join(centroids) %>%
select(centroid_long, centroid_lat) %>%
as.matrix()
#find nearest neighbours - we set k to 25 here
neighbours <- knn2nb(knearneigh(props_centroid_matrix, k = 25, longlat = TRUE))
#calculate distances between neighbours
distances <- nbdists(neighbours, props_centroid_matrix, longlat = TRUE)Step 4: set the weights in the spatial weights matrix to be the reciprocal distance (1/x), so that closer neighbours = smaller distance = higher weight = more influence in the smoothing. In other words, we don’t just consider 25 nearest neighbours in the smoothing - we apply more weight to the nearer of those nearest neighbours.
#weighting of the neighbors by reciprocal distance
recip_distances <- lapply(distances, function(x) 1/x)
#return this in a format for spdep
swm <- nb2listw(neighbours, recip_distances)Step 5: Calculate the Getis-Ord Gi* statistic, the technical term for our hotspot analysis, using localG() and providing it with our aggregated values (in the prop column of our props dataframe) and the spatial weights matrix we just made (swm). Here, we add this back to the props dataframe in a column called z
props <- props %>%
mutate(z = as.numeric(localG(prop, swm)))Now let’s plot the values of z and marvel at the smoothness! Note how we’ve used scale_fill_viridis(), which is a nice colour palette for reasons explained here - you first need to install and load the viridis package if you want to use it though.
uk.districts %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = z)) +
scale_fill_viridis() +
theme_void()
To make comparisons easier, let’s plot the raw map and smoothed map next to each other (install and load in the patchwork package to display plots side-by-side like this)
raw.map <- uk.districts %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = prop)) +
scale_fill_viridis() +
theme_void()
smooth.map <- uk.districts %>%
left_join(props) %>%
ggplot() +
geom_sf(aes(fill = z)) +
scale_fill_viridis() +
theme_void()
raw.map + smooth.map
Notice how the smoothing algorithm has smoothed over those random yellow-coloured polygons dotted here and there, and instead highlighted a hotspot focused around the obvious cluster in the East Midlands. This is good! Those isolated yellow postcode districts are almost certainly outliers, misleadingly calculated at 100% most likely based on a single person. At this level of geographic granularity, there’s no way you’d genuinely get such a localised pattern specific to one tiny postcode district and not the surrounding ones! (but if anyone knows of such a dialectal pattern, I’m all ears).
Let’s zoom into the Midlands to get a clearer comparison:
raw.map <- raw.map + coord_sf(ylim = c(52, 54), xlim = c(-3, 0))
smooth.map <- smooth.map + coord_sf(ylim = c(52, 54), xlim = c(-3, 0))
raw.map + smooth.map
The smoothed map isn’t perfect. There are still lots of grey/blank polygons, because localG() can’t do anything with geometries that have missing values. We would have to manually interpolate these values, which is possible (and what we did in the Journal of Linguistic Geography paper) but that is sadly beyond the scope of this workshop!
Exercise
- Try plotting some smoothed maps and compare them to raw maps. While doing this, experiment with different values of k to see how it influences the output.
- Perform the local autocorrelation smoothing but plot it as an interactive map using
mapview()so you can zoom in and explore the smoothing
Still here? Well here’s some bonus content for you!
Conducting hot spot analysis in the way we just did can sometimes introduce a weird smoothing artefact that I like to call the ‘donut problem’. Compare the raw and smoothed maps below (k = 5 in the hotspot analysis)

When we get one isolated polygon with a high value, surrounded by others with lower values, the smoothing actually creates a donut-type pattern where the surrounding polygons get higher z-scores than the polygon that did actually have the high value to begin with! This doesn’t seem like a very good system, and it arises because of how the nearest neighbour calculation works: each polygon is assigned a z-score based on the values of its k nearest neighbours, as we’ve already established, but in the default version of this algorithm each polygon doesn’t take itself into account.
We can fix this if we change the nearest neighbour search as shown below. Notice we lower the value of k by 1, because we then use include.self() so that each polygon includes itself alongside its 9 other nearest neighbours.
neighbours <- knn2nb(knearneigh(matrix, k = 4, longlat = TRUE))
neighbours <- include.self(neighbours)
distances <- nbdists(neighbours, matrix, longlat = TRUE)
recip_distances <- lapply(distances, function(x) 1/x)However, we run into a problem when we compute a spatial weights matrix based on reciprocal distance, because each polygon now has itself as a nearest neighbour, which obviously has a distance from itself of 0, and we can’t take the reciprocal of 0!
Solution? Before we calculate the reciprocal distances, we actually run the following loop to go through each set of distances and replace the 0 with the next smallest distance in the set (divided by 2, but this is somewhat arbitrary - it should just be the smallest number in the set but greater than 0)
for (x in 1:length(distances)) {
distances[[x]] = replace(distances[[x]],
distances[[x]] == 0,
sort(distances[[x]])[2]/2)
}If we add the above into our workflow, here’s what the new smoothing looks like:

Hooray, no donuts!